You don't need EfficientNets. Simple tricks make ResNets better and faster than EfficientNets
Revisiting ResNets: Improved Training and Scaling Strategies. New family of architectures - ResNet-RS.
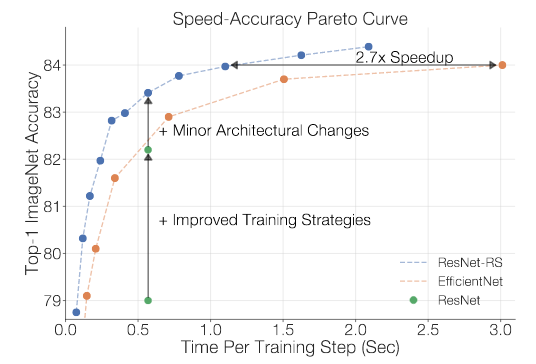
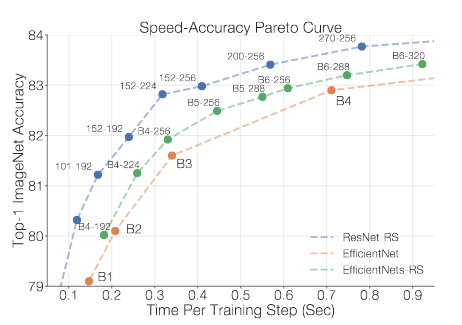
In this post I will give a brief overview over the recent paper from Google Brain and UC Berkeley Revisiting ResNets: Improved Training and Scaling Strategies. Authors introduce a new family of ResNet architectures– ResNet-RS.
🔥 Main Results
- ResNet-RSs are 1.7x - 2.7x faster than EfficientNets on TPUs, while achieving similar or better accuracies on ImageNet.
- In semi-supervised learning scenario (w/ 130M pseudo-labaled images) ResNet-RS achieves 86.2% top-1 ImageNet accuracy, while being 4.7x faster than EfficientNet-NoisyStudent – SoTA results for transfer learning.
🃏 Authors take advantage of the following ideas:
- Convolutions are better optimized for GPUs/TPUs than depthwise convolutions used in EfficientNets.
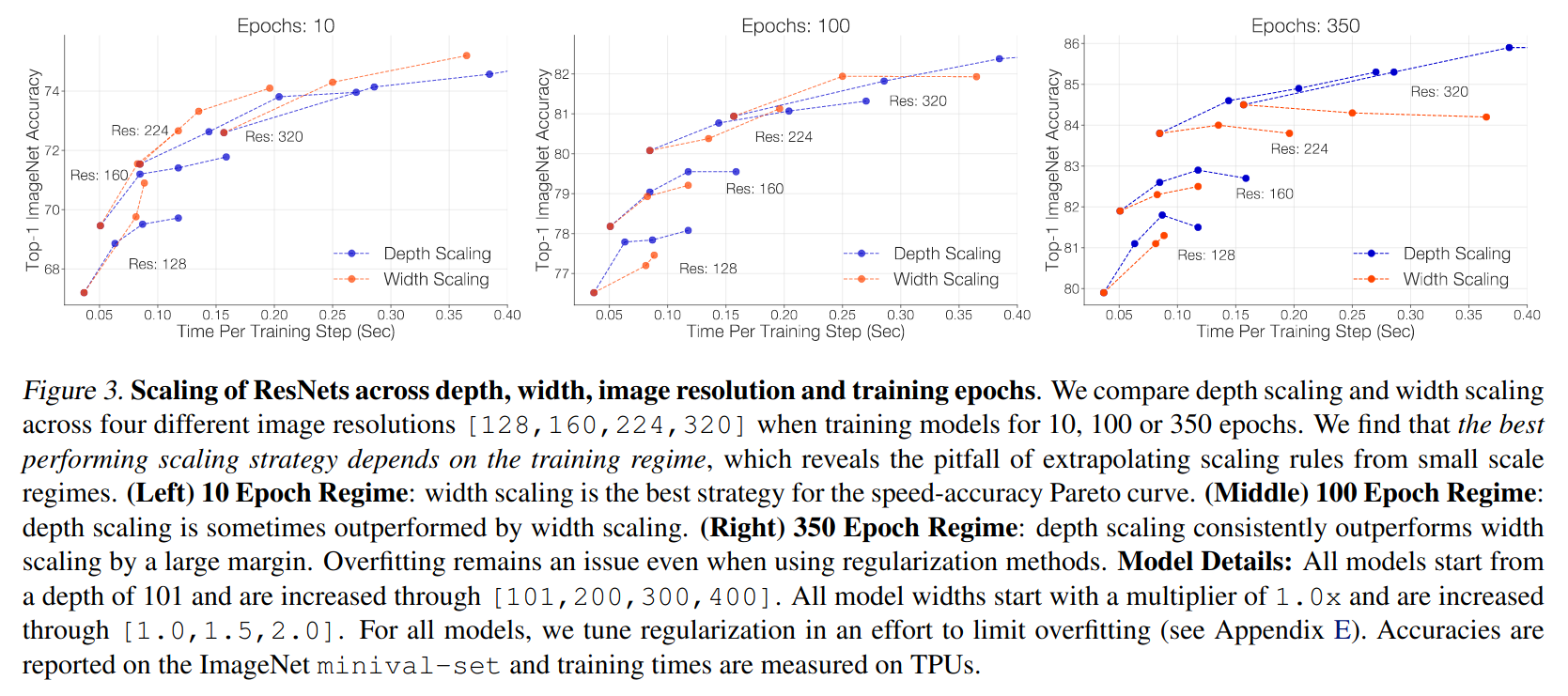
- Simple Scaling Strategy (i.e. Increasing the model dimensions like width, depth and resolution) is the key. Scale model depth in regimes where overfitting can occur:
🔸Depth scaling outperforms width scaling for longer epoch regimes.
🔸Width scaling outperforms depth scaling for shorter epoch regimes. - Apply weight decay, label smoothing, dropout and stochastic depth for regularization.
- Use RandAugment instead of AutoAugment.
- Adding two common and simple architectural changes: Squeeze-and-Excitation and ResNet-D tricks.
- Decrease weight decay when using more regularization like dropout, augmentations, stochastic depth, etc.
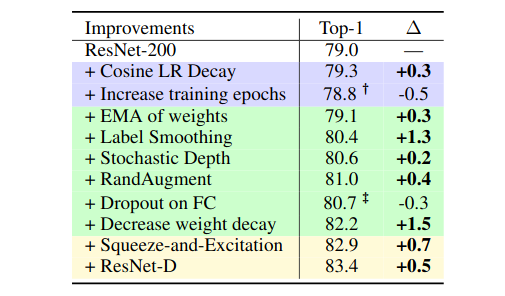
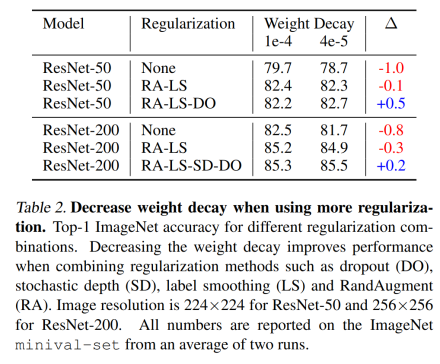
❓How to tune the hyperparameters?
- Scaling strategies found in small-scale regimes (e.g. on small models or with few training epochs) fail to generalize to larger models or longer training iterations
- Run a small subset of models across different scales, for the full training epochs, to gain intuition on which dimensions are the most useful across model scales.
- Increase Image Resolution lower than previously recommended. Larger image resolutions often yield diminishing returns.
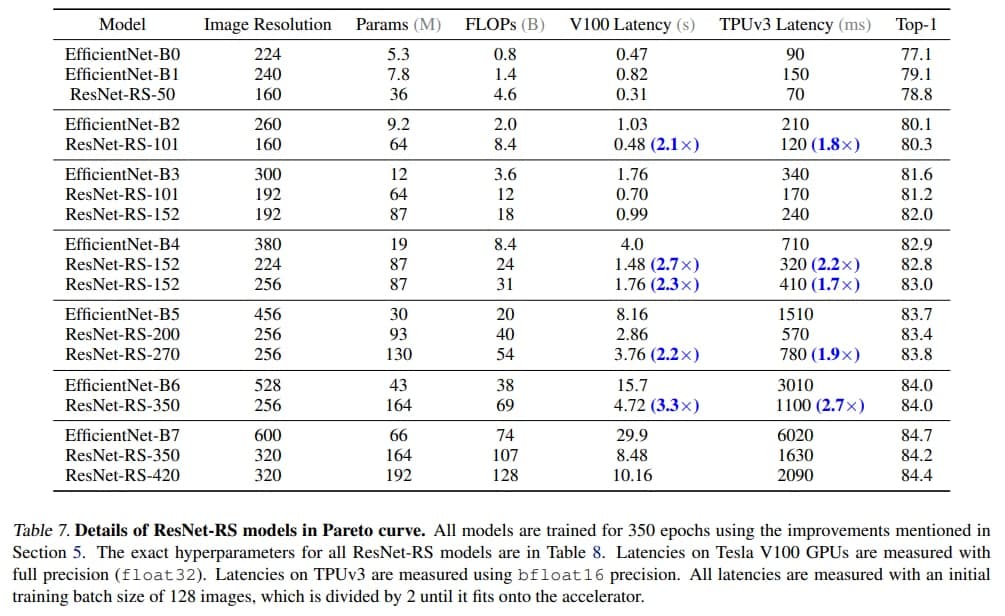
⚔️FLOPs vs Latency
While FLOPs provide a hardware-agnostic metric for assessing computational demand, they may not be indicative of actual latency times for training and inference. In custom hardware architectures (e.g. TPUs and GPUs), FLOPs are an especially poor proxy because operations are often bounded by memory access costs and have different levels of optimization on modern matrix multiplication units. The inverted bottlenecks used in EfficientNets employ depthwise convolutions with large activations and have a small compute to memory ratio (operational intensity) compared to the ResNet’s bottleneck blocks which employ dense convolutions on smaller activations. This makes EfficientNets less efficient 😂 on modern accelerators compared to ResNets. A ResNet-RS model with 1.8x more FLOPs than EfficientNet-B6 is 2.7x faster on a TPUv3.
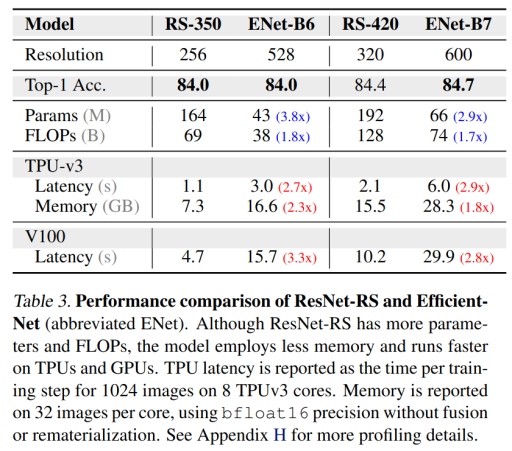
⚔️ Parameters vs Memory
Although ResNet-RS has 3.8x more parameters and FLOPs than EfficeintNet with the same accuracy, the ResNet-RS model requires 2.3x less memory and runs ~3x faster on TPUs and GPUs. Parameter count does not necessarily dictate memory consumption during training because memory is often dominated by the size of the activations. And EfficientNets has large activations which cause a larger memory footprint because EfficientNets requires large image resolutions to match the performance of the ResNet-RSs. E.g, to get 84% top-1 ImageNet accuracy, EficientNet needs an input image of 528x528, while ResNet-RS - only 256x256.
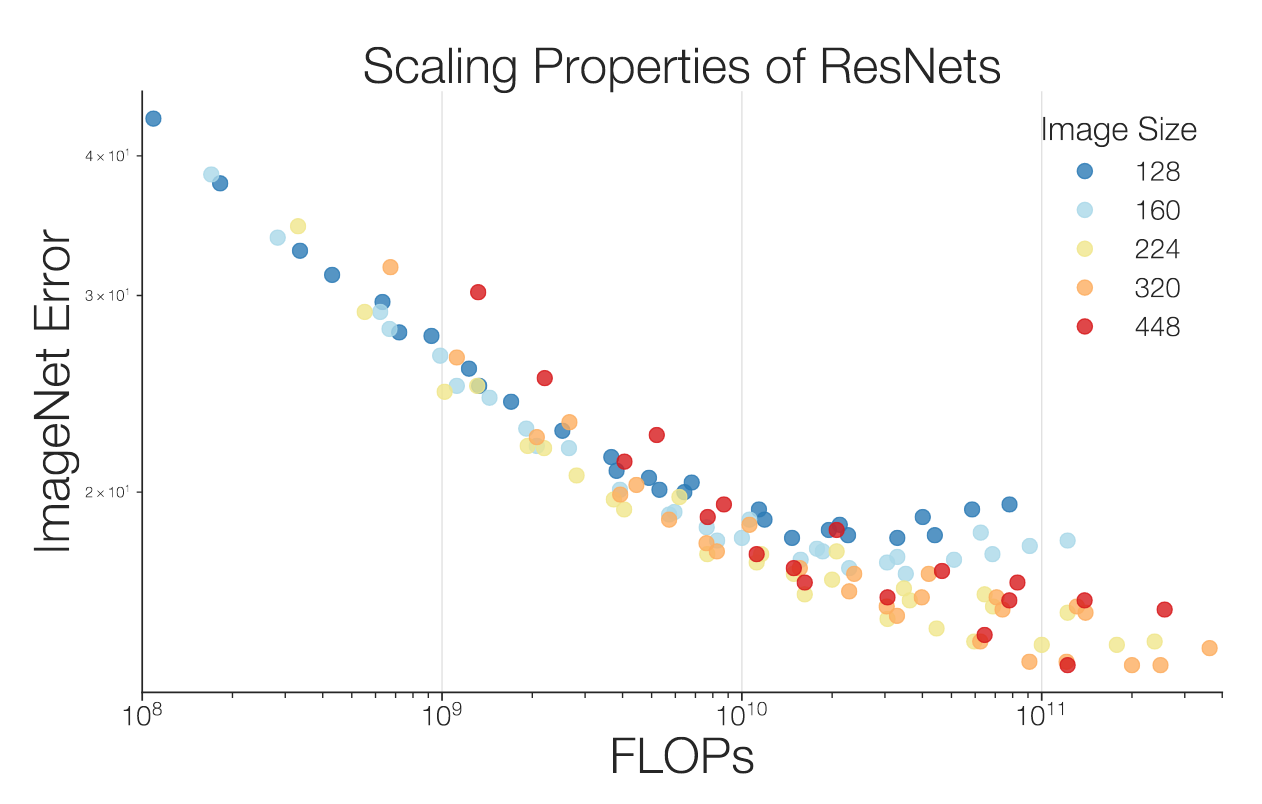
More results
You'd better use ResNets as baselines for your projects from now on.
☑️ Conclusions:
- You’d better use ResNets as baselines for your projects from now on.
- Reporting latencies and memory consumption are generally more relevant metrics to compare different architectures, than the number of FLOPs. FLOPs and parameters are not representative of latency or memory consumption.
- Training methods can be more task-specific than architectures. E.g., data augmentation is useful for small datasets or when training for many epochs, but the specifics of the augmentation method can be task-dependent (e.g. scale jittering instead of RandAugment is better on Kinetics-400 video classification).
- The best performing scaling strategy depends on the training regime and whether overfitting is an issue. When training for 350 epochs on ImageNet, use depth scaling, whereas scaling the width is preferable when training for few epochs (e.g. only 10)
- Future successful architectures will probably emerge by co-design with hardware, particularly in resource-tight regimes like mobile phones.
🌐 Links
📝 Revisiting ResNets: Improved Training and Scaling Strategies
🔨 Tensorflow implementation
📎 Other references:
Feel free to ask me any questions in the comments below. Feedback is also very appreciated.
- Join my telegram channel for more reviews like this
 @gradientdude
@gradientdude - Follow me on twitter
 @artsiom_s
@artsiom_s