 |
|
About me
I'm currently a Research Scientist in the industry (one of the FAANG companies). I obtained a PhD degree in Computer Vision from Heidelberg University under the supervision of Björn Ommer. I'm a Kaggle competitions Master (ranked Top 50 worldwide). 2x AI Research intern.
News
▻ 06/2021. I joined Reality Labs in Zürich!
▻ 06/2021. Our team was awarded 3rd place within the Waymo Motion Prediction Challenge!
▻ 04/2021. I have defended my PhD dissertation on "Visual Representation Learning with Limited Supervision"!
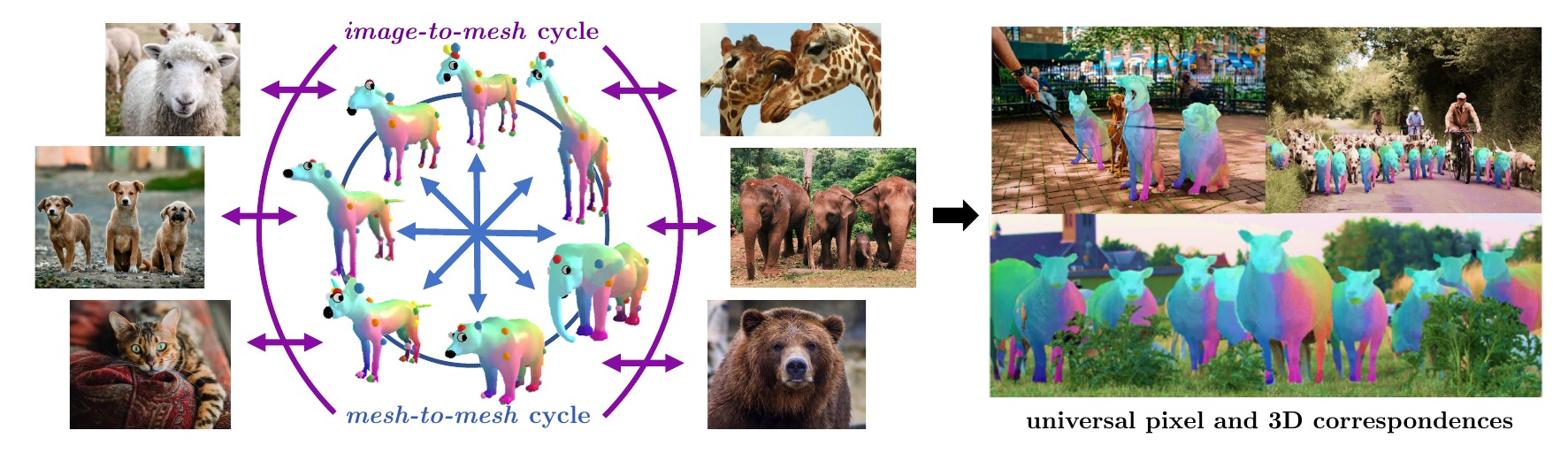
▻ 02/2021. Our paper Discovering Relationships between Object Categories via Universal Canonical Maps was accepted at CVPR 2021.
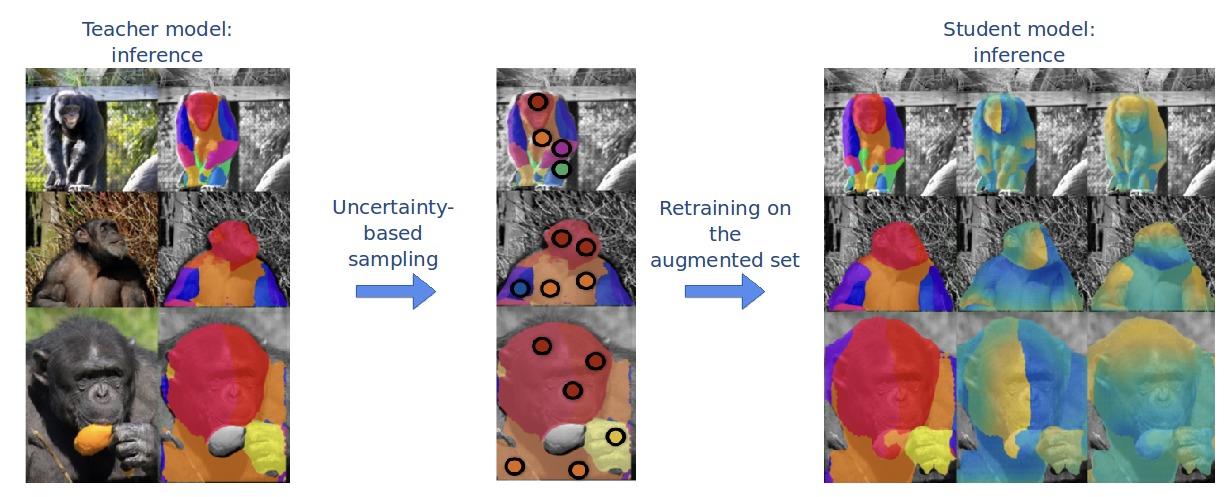
▻ 02/2020. Our paper Transferring Dense Pose to Proximal Animal Classes was accepted at CVPR 2020.
▻ 09/2019. I was ranked as one of the best reviewers at NeurIPS 2019 (top 400).
▻ 09/2019. Started internship at AI Research (with Andrea Vedaldi and Natalia Neverova).
▻ 08/2019. Our paper Semi-Supervised Segmentation of Salt Bodies in Seismic Images using an Ensemble of Convolutional Neural Networks was accepted at GCPR 2019 [Oral].
▻ 08/2019. Our paper Content and Style Disentanglement for Artistic Style Transfer was accepted at ICCV 2019.
▻ 07/2019. Invited talk at SIAM chapter in Heidelberg: Identification of Humpback Whales using Deep Metric Learning
▻ 2 papers accepted at CVPR 2019.
▻ My team finished 10th (out of 2131 teams) in Humpback Whale Identification challenge on Kaggle. Tweet.
▻ Our paper A Style-Aware Content Loss for Real-time HD Style Transfer was accepted at ECCV 2018 [Oral].
Selected Papers
|
Discovering Relationships between Object Categories via Universal Canonical Maps
Natalia Neverova*, Artsiom Sanakoyeu*, Patrick Labatut, David Novotny, Andrea Vedaldi CVPR 2021. [Paper] [Website] |
|
|
Transferring Dense Pose to Proximal Animal Classes
Artsiom Sanakoyeu, Vasil Khalidov, Maureen S. McCarthy, Andrea Vedaldi, Natalia Neverova CVPR 2020. [Paper] [Website] [Code] [Video] |
|
|
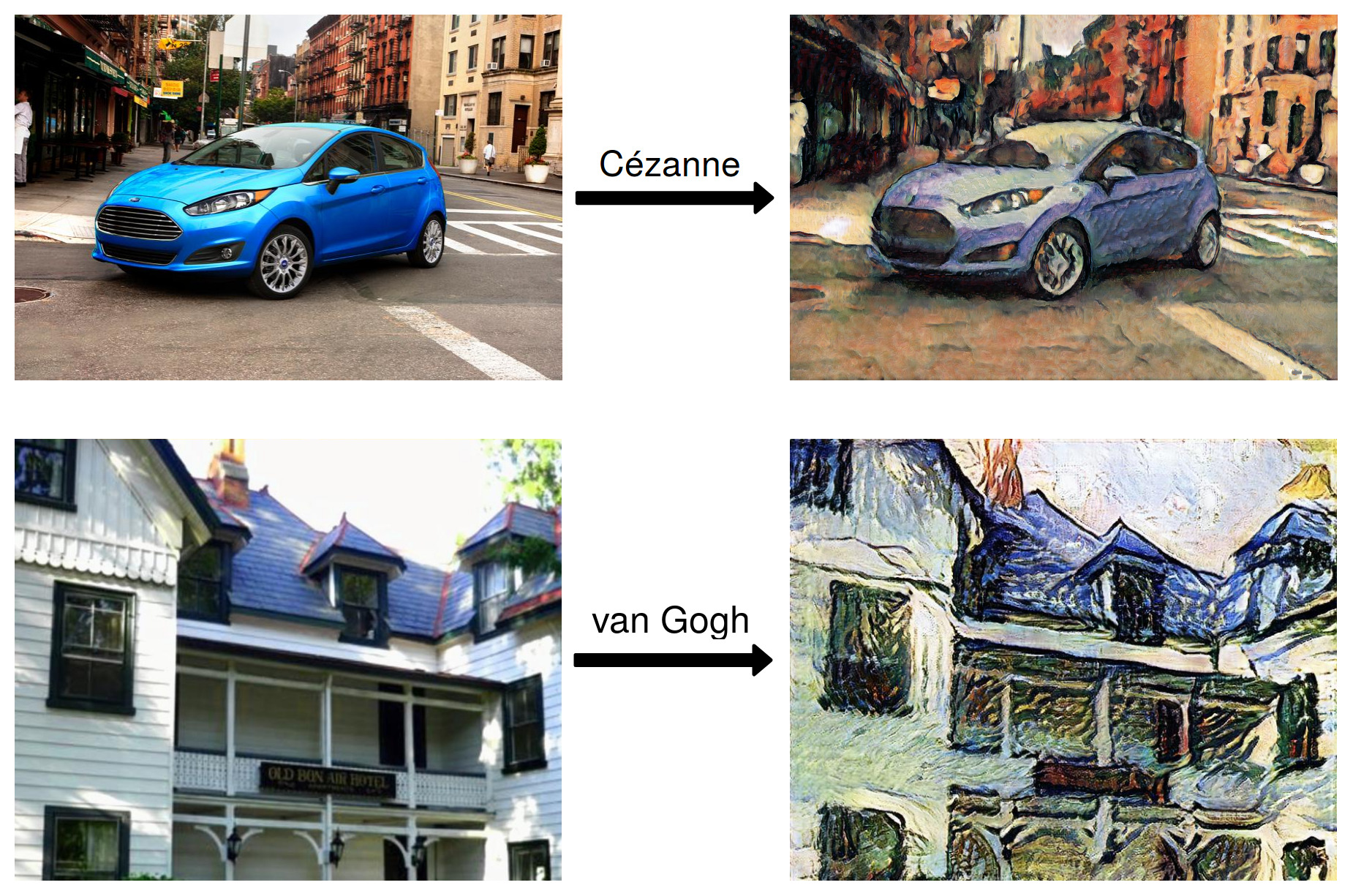
Content and Style Disentanglement for Artistic Style Transfer
Dmytro Kotovenko, Artsiom Sanakoyeu, Sabine Lang, Björn Ommer ICCV 2019. [Paper] [Website] [Code] [Video] |
|
|
Semi-Supervised Segmentation of Salt Bodies in Seismic Images using an Ensemble of Convolutional Neural Networks
Yauhen Babakhin, Artsiom Sanakoyeu, Hirotoshi Kitamura German Conference on Pattern Recognition (GCPR), 2019. [Paper] [Code] |
|
|
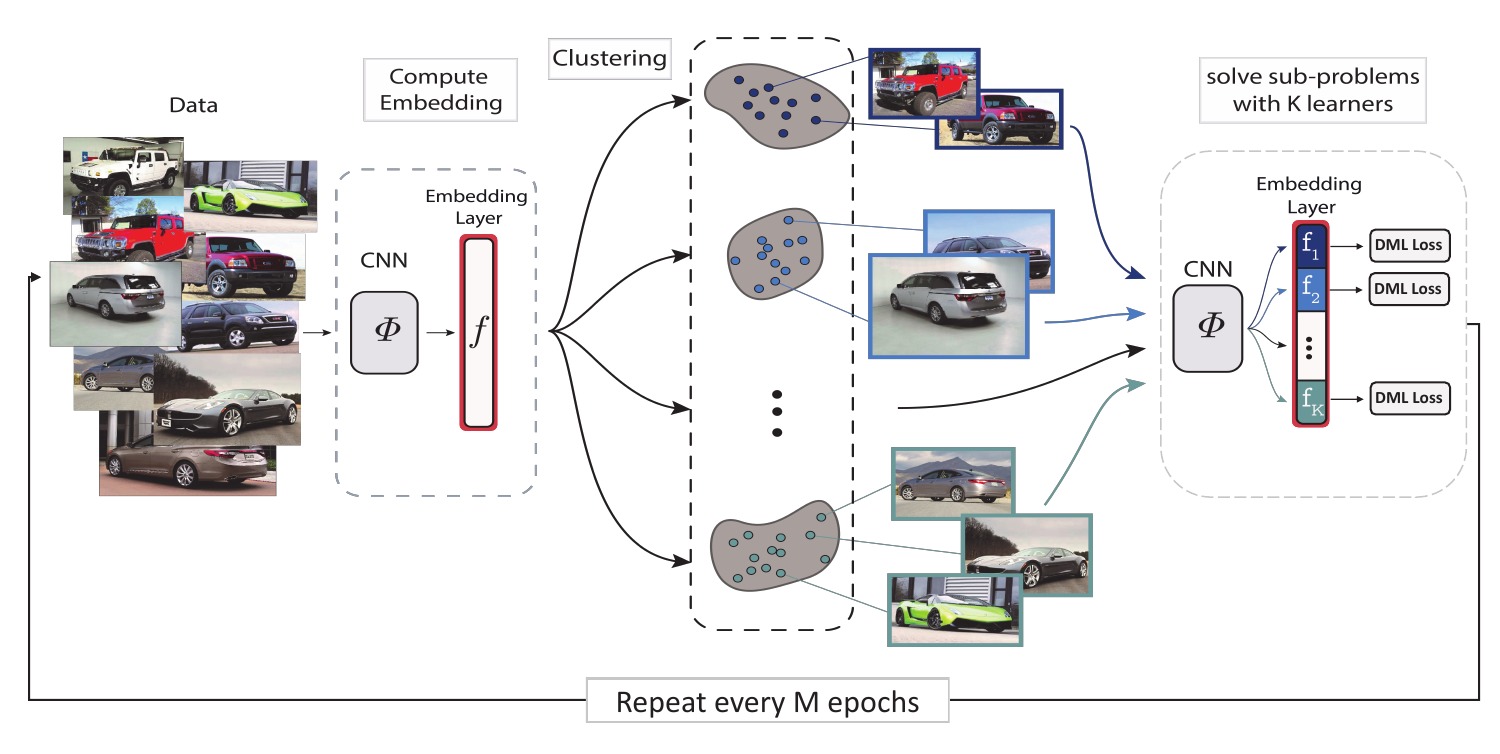
Divide and Conquer the Embedding Space for Metric Learning
Artsiom Sanakoyeu, Vadim Tschernezki, Uta Büchler, Björn Ommer CVPR 2019. [Paper] [Code] |
|
|
A Content Transformation Block for Image Style Transfer
Dmytro Kotovenko, Artsiom Sanakoyeu, Pingchuan Ma, Sabine Lang, Björn Ommer CVPR 2019. [Paper] [Website] [Code] |
|
|
A Style-Aware Content Loss for Real-time HD Style Transfer
Artsiom Sanakoyeu*, Dmytro Kotovenko*, Sabine Lang, Björn Ommer ECCV 2018 (Oral). [Paper] [Website] [Code] |
|
|
Deep Unsupervised Learning of Visual Similarities
Artsiom Sanakoyeu, Miguel Bautista, Björn Ommer Pattern Recognition. 78, 2018. [Paper] [Video] [Website] |
|
|
Deep Unsupervised Similarity Learning using Partially Ordered Sets
Miguel Bautista*, Artsiom Sanakoyeu*, Björn Ommer CVPR 2017. [Paper] [Video] [Code] |
|
|
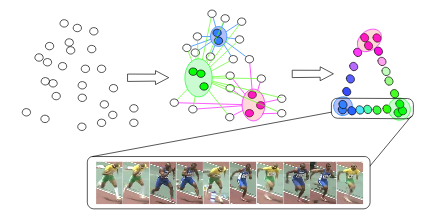
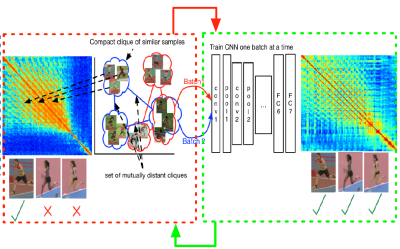
CliqueCNN: Deep Unsupervised Exemplar Learning
Miguel Bautista*, Artsiom Sanakoyeu*, Björn Ommer NIPS 2016. [Paper] [Video] [Website] [Code] [Presentation] |

Other Projects
|
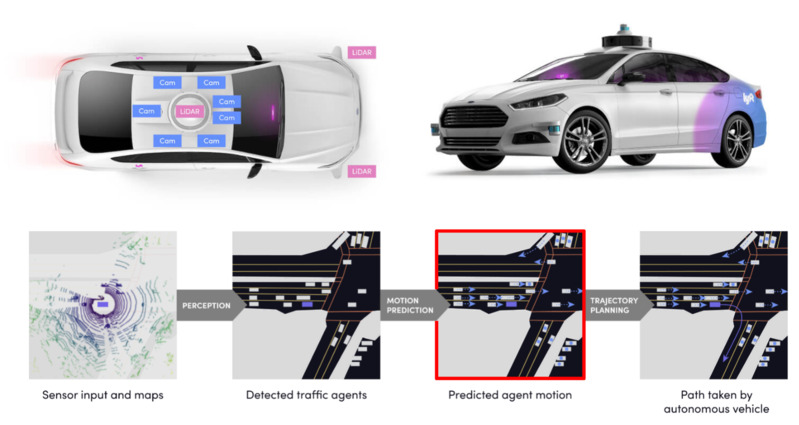
3st place: Lyft Motion Prediction for Autonomous Vehicles on Kaggle
Problem: build a model that reliably predicts the movement of traffic agents around the Autonomous Vehicle, such as cars, cyclists, and pedestrians. 3rd place out of 935 teams, Kaggle.com, 2020 [Blogpost] [Leaderboard] [Code] [Video] |
|
|
1st place: Carvana Image Masking Challenge on Kaggle
Carvana, a successful online used car startup, challenged the Kaggle community to develop an algorithm that automatically removes the photo background. 1st place out of 735 participants, Kaggle.com, 2017 [Blogpost] [Leaderboard] [Code] |

Invited Talks
|
Identification of Humpback Whales using Deep Metric Learning
Society for Industrial and Applied Mathematics (SIAM), Heidelberg, July 2019 [Slides] |

Review activities
NeurIPS (Best Reviewer 2020, 2019), ICLR, ICML, ICCV, CVPR, ECCV, SIGGRAPH, IEEE Transactions on Image Processing